Tuning models with Optuna#
In this notebook we will see how to tune the hyperparameters of a GlutonTS model using Optuna. For this example, we are going to tune a PyTorch-based DeepAREstimator.
Note: to keep the running time of this example short, here we consider a small-scale dataset, and tune only two hyperparameters over a very small number of tuning rounds (“trials”). In real applications, especially for larger datasets, you will probably need to increase the search space and increase the number of trials.
Data loading and processing#
[1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import json
Provided datasets#
[2]:
from gluonts.dataset.repository.datasets import get_dataset, dataset_recipes
from gluonts.dataset.util import to_pandas
[3]:
print(f"Available datasets: {list(dataset_recipes.keys())}")
Available datasets: ['constant', 'exchange_rate', 'solar-energy', 'electricity', 'traffic', 'exchange_rate_nips', 'electricity_nips', 'traffic_nips', 'solar_nips', 'wiki-rolling_nips', 'taxi_30min', 'kaggle_web_traffic_with_missing', 'kaggle_web_traffic_without_missing', 'kaggle_web_traffic_weekly', 'm1_yearly', 'm1_quarterly', 'm1_monthly', 'nn5_daily_with_missing', 'nn5_daily_without_missing', 'nn5_weekly', 'tourism_monthly', 'tourism_quarterly', 'tourism_yearly', 'cif_2016', 'london_smart_meters_without_missing', 'wind_farms_without_missing', 'car_parts_without_missing', 'dominick', 'fred_md', 'pedestrian_counts', 'hospital', 'covid_deaths', 'kdd_cup_2018_without_missing', 'weather', 'm3_monthly', 'm3_quarterly', 'm3_yearly', 'm3_other', 'm4_hourly', 'm4_daily', 'm4_weekly', 'm4_monthly', 'm4_quarterly', 'm4_yearly', 'm5', 'uber_tlc_daily', 'uber_tlc_hourly', 'airpassengers']
[4]:
dataset = get_dataset("m4_hourly")
Extract and split training and test data sets#
In general, the datasets provided by GluonTS are objects that consists of three things:
dataset.trainis an iterable collection of data entries used for training. Each entry corresponds to one time seriesdataset.testis an iterable collection of data entries used for inference. The test dataset is an extended version of the train dataset that contains a window in the end of each time series that was not seen during training. This window has length equal to the recommended prediction length.dataset.metadatacontains metadata of the dataset such as the frequency of the time series, a recommended prediction horizon, associated features, etc.
We can check details of the dataset.metadata.
[5]:
print(f"Recommended prediction horizon: {dataset.metadata.prediction_length}")
print(f"Frequency of the time series: {dataset.metadata.freq}")
Recommended prediction horizon: 48
Frequency of the time series: H
This is what the data looks like (first training series, first two weeks of data)
[6]:
to_pandas(next(iter(dataset.train)))[: 14 * 24].plot()
plt.grid(which="both")
plt.legend(["train series"], loc="upper left")
plt.show()
Tuning parameters of DeepAR estimator#
[7]:
import optuna
import torch
from gluonts.dataset.split import split
from gluonts.evaluation import Evaluator
from gluonts.torch.model.deepar import DeepAREstimator
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
We will now tune the DeepAR estimator on our training data using Optuna. We choose two hyperparameters num_layers and hidden_size to optimize.
First, we define a dataentry_to_dataframe method to transform a DataEntry into a pandas.DataFrame. Second, we define an DeepARTuningObjective class used in tuning process of Optuna. The class can be configured with the dataset, prediction length and data frequency, and the metric to be used for evaluating the model. In the __init__ method, we initialize the objective and split the dataset using split method existed in our GluonTS project. - validation_input: the input
part used in validation - validation_label: the label part used in validation In the get_params method, we define what hyperparameters to be tuned within given range. In the __call__ method, we define the way the DeepAREstimator is used in training and validation.
[8]:
def dataentry_to_dataframe(entry):
df = pd.DataFrame(
entry["target"],
columns=[entry.get("item_id")],
index=pd.period_range(
start=entry["start"], periods=len(entry["target"]), freq=entry["start"].freq
),
)
return df
class DeepARTuningObjective:
def __init__(
self, dataset, prediction_length, freq, metric_type="mean_wQuantileLoss"
):
self.dataset = dataset
self.prediction_length = prediction_length
self.freq = freq
self.metric_type = metric_type
self.train, test_template = split(dataset, offset=-self.prediction_length)
validation = test_template.generate_instances(
prediction_length=prediction_length
)
self.validation_input = [entry[0] for entry in validation]
self.validation_label = [
dataentry_to_dataframe(entry[1]) for entry in validation
]
def get_params(self, trial) -> dict:
return {
"num_layers": trial.suggest_int("num_layers", 1, 5),
"hidden_size": trial.suggest_int("hidden_size", 10, 50),
}
def __call__(self, trial):
params = self.get_params(trial)
estimator = DeepAREstimator(
num_layers=params["num_layers"],
hidden_size=params["hidden_size"],
prediction_length=self.prediction_length,
freq=self.freq,
trainer_kwargs={
"enable_progress_bar": False,
"enable_model_summary": False,
"max_epochs": 10,
},
)
predictor = estimator.train(self.train, cache_data=True)
forecast_it = predictor.predict(self.validation_input)
forecasts = list(forecast_it)
evaluator = Evaluator(quantiles=[0.1, 0.5, 0.9])
agg_metrics, item_metrics = evaluator(
self.validation_label, forecasts, num_series=len(self.dataset)
)
return agg_metrics[self.metric_type]
We can now invoke the Optuna tuning process.
[9]:
import time
start_time = time.time()
study = optuna.create_study(direction="minimize")
study.optimize(
DeepARTuningObjective(
dataset.train, dataset.metadata.prediction_length, dataset.metadata.freq
),
n_trials=5,
)
print("Number of finished trials: {}".format(len(study.trials)))
print("Best trial:")
trial = study.best_trial
print(" Value: {}".format(trial.value))
print(" Params: ")
for key, value in trial.params.items():
print(" {}: {}".format(key, value))
print(time.time() - start_time)
[I 2023-05-11 12:07:43,479] A new study created in memory with name: no-name-d8947684-e697-40fa-9db1-7a13ea5b3e93
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/utilities/parsing.py:270: UserWarning: Attribute 'model' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['model'])`.
f"Attribute {k!r} is an instance of `nn.Module` and is already saved during checkpointing."
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/trainer/connectors/logger_connector/logger_connector.py:68: UserWarning: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `pytorch_lightning` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
"Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `pytorch_lightning`"
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:110: PossibleUserWarning: You defined a `validation_step` but have no `val_dataloader`. Skipping val loop.
category=PossibleUserWarning,
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 50: 'train_loss' reached 5.89946 (best 5.89946), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_1/checkpoints/epoch=0-step=50.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 100: 'train_loss' reached 5.27020 (best 5.27020), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_1/checkpoints/epoch=1-step=100.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 150: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 3, global step 200: 'train_loss' reached 5.16709 (best 5.16709), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_1/checkpoints/epoch=3-step=200.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 4, global step 250: 'train_loss' reached 4.78433 (best 4.78433), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_1/checkpoints/epoch=4-step=250.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 5, global step 300: 'train_loss' reached 4.52828 (best 4.52828), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_1/checkpoints/epoch=5-step=300.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 6, global step 350: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 7, global step 400: 'train_loss' reached 4.51077 (best 4.51077), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_1/checkpoints/epoch=7-step=400.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 8, global step 450: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 9, global step 500: 'train_loss' reached 4.44126 (best 4.44126), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_1/checkpoints/epoch=9-step=500.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=10` reached.
Running evaluation: 100%|██████████| 414/414 [00:00<00:00, 17321.98it/s]
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pandas/core/dtypes/cast.py:1201: UserWarning: Warning: converting a masked element to nan.
return arr.astype(dtype, copy=True)
[I 2023-05-11 12:08:21,947] Trial 0 finished with value: 0.05520475880267988 and parameters: {'num_layers': 3, 'hidden_size': 17}. Best is trial 0 with value: 0.05520475880267988.
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/utilities/parsing.py:270: UserWarning: Attribute 'model' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['model'])`.
f"Attribute {k!r} is an instance of `nn.Module` and is already saved during checkpointing."
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:110: PossibleUserWarning: You defined a `validation_step` but have no `val_dataloader`. Skipping val loop.
category=PossibleUserWarning,
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 50: 'train_loss' reached 5.79182 (best 5.79182), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_2/checkpoints/epoch=0-step=50.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 100: 'train_loss' reached 5.00468 (best 5.00468), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_2/checkpoints/epoch=1-step=100.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 150: 'train_loss' reached 4.94047 (best 4.94047), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_2/checkpoints/epoch=2-step=150.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 3, global step 200: 'train_loss' reached 4.88823 (best 4.88823), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_2/checkpoints/epoch=3-step=200.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 4, global step 250: 'train_loss' reached 4.71590 (best 4.71590), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_2/checkpoints/epoch=4-step=250.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 5, global step 300: 'train_loss' reached 4.22663 (best 4.22663), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_2/checkpoints/epoch=5-step=300.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 6, global step 350: 'train_loss' reached 4.22133 (best 4.22133), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_2/checkpoints/epoch=6-step=350.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 7, global step 400: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 8, global step 450: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 9, global step 500: 'train_loss' reached 4.15383 (best 4.15383), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_2/checkpoints/epoch=9-step=500.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=10` reached.
Running evaluation: 100%|██████████| 414/414 [00:00<00:00, 17195.05it/s]
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pandas/core/dtypes/cast.py:1201: UserWarning: Warning: converting a masked element to nan.
return arr.astype(dtype, copy=True)
[I 2023-05-11 12:09:12,733] Trial 1 finished with value: 0.05533707998288512 and parameters: {'num_layers': 3, 'hidden_size': 37}. Best is trial 0 with value: 0.05520475880267988.
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/utilities/parsing.py:270: UserWarning: Attribute 'model' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['model'])`.
f"Attribute {k!r} is an instance of `nn.Module` and is already saved during checkpointing."
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:110: PossibleUserWarning: You defined a `validation_step` but have no `val_dataloader`. Skipping val loop.
category=PossibleUserWarning,
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 50: 'train_loss' reached 5.62167 (best 5.62167), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_3/checkpoints/epoch=0-step=50.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 100: 'train_loss' reached 5.30221 (best 5.30221), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_3/checkpoints/epoch=1-step=100.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 150: 'train_loss' reached 5.14853 (best 5.14853), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_3/checkpoints/epoch=2-step=150.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 3, global step 200: 'train_loss' reached 5.11902 (best 5.11902), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_3/checkpoints/epoch=3-step=200.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 4, global step 250: 'train_loss' reached 4.71378 (best 4.71378), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_3/checkpoints/epoch=4-step=250.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 5, global step 300: 'train_loss' reached 4.70526 (best 4.70526), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_3/checkpoints/epoch=5-step=300.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 6, global step 350: 'train_loss' reached 4.60291 (best 4.60291), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_3/checkpoints/epoch=6-step=350.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 7, global step 400: 'train_loss' reached 4.30428 (best 4.30428), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_3/checkpoints/epoch=7-step=400.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 8, global step 450: 'train_loss' reached 4.24524 (best 4.24524), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_3/checkpoints/epoch=8-step=450.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 9, global step 500: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=10` reached.
Running evaluation: 100%|██████████| 414/414 [00:00<00:00, 19309.46it/s]
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pandas/core/dtypes/cast.py:1201: UserWarning: Warning: converting a masked element to nan.
return arr.astype(dtype, copy=True)
[I 2023-05-11 12:10:24,877] Trial 2 finished with value: 0.06328460733159344 and parameters: {'num_layers': 4, 'hidden_size': 48}. Best is trial 0 with value: 0.05520475880267988.
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/utilities/parsing.py:270: UserWarning: Attribute 'model' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['model'])`.
f"Attribute {k!r} is an instance of `nn.Module` and is already saved during checkpointing."
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:110: PossibleUserWarning: You defined a `validation_step` but have no `val_dataloader`. Skipping val loop.
category=PossibleUserWarning,
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 50: 'train_loss' reached 5.54284 (best 5.54284), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_4/checkpoints/epoch=0-step=50.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 100: 'train_loss' reached 5.06998 (best 5.06998), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_4/checkpoints/epoch=1-step=100.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 150: 'train_loss' reached 4.81164 (best 4.81164), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_4/checkpoints/epoch=2-step=150.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 3, global step 200: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 4, global step 250: 'train_loss' reached 4.56830 (best 4.56830), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_4/checkpoints/epoch=4-step=250.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 5, global step 300: 'train_loss' reached 4.11064 (best 4.11064), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_4/checkpoints/epoch=5-step=300.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 6, global step 350: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 7, global step 400: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 8, global step 450: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 9, global step 500: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=10` reached.
Running evaluation: 100%|██████████| 414/414 [00:00<00:00, 16246.35it/s]
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pandas/core/dtypes/cast.py:1201: UserWarning: Warning: converting a masked element to nan.
return arr.astype(dtype, copy=True)
[I 2023-05-11 12:11:05,867] Trial 3 finished with value: 0.04293582101270954 and parameters: {'num_layers': 2, 'hidden_size': 48}. Best is trial 3 with value: 0.04293582101270954.
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/utilities/parsing.py:270: UserWarning: Attribute 'model' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['model'])`.
f"Attribute {k!r} is an instance of `nn.Module` and is already saved during checkpointing."
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:110: PossibleUserWarning: You defined a `validation_step` but have no `val_dataloader`. Skipping val loop.
category=PossibleUserWarning,
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 50: 'train_loss' reached 6.50022 (best 6.50022), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_5/checkpoints/epoch=0-step=50.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 100: 'train_loss' reached 5.40657 (best 5.40657), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_5/checkpoints/epoch=1-step=100.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 150: 'train_loss' reached 5.21517 (best 5.21517), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_5/checkpoints/epoch=2-step=150.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 3, global step 200: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 4, global step 250: 'train_loss' reached 5.17837 (best 5.17837), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_5/checkpoints/epoch=4-step=250.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 5, global step 300: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 6, global step 350: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 7, global step 400: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 8, global step 450: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 9, global step 500: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=10` reached.
Running evaluation: 100%|██████████| 414/414 [00:00<00:00, 20986.22it/s]
/opt/hostedtoolcache/Python/3.7.16/x64/lib/python3.7/site-packages/pandas/core/dtypes/cast.py:1201: UserWarning: Warning: converting a masked element to nan.
return arr.astype(dtype, copy=True)
[I 2023-05-11 12:12:02,327] Trial 4 finished with value: 0.11596933031940504 and parameters: {'num_layers': 5, 'hidden_size': 17}. Best is trial 3 with value: 0.04293582101270954.
Number of finished trials: 5
Best trial:
Value: 0.04293582101270954
Params:
num_layers: 2
hidden_size: 48
258.85356855392456
Re-training the model#
After getting the best hyperparameters by optuna, you can set them into the DeepAR estimator to re-train the model on the whole training subset we consider here.
[10]:
estimator = DeepAREstimator(
num_layers=trial.params["num_layers"],
hidden_size=trial.params["hidden_size"],
prediction_length=dataset.metadata.prediction_length,
context_length=100,
freq=dataset.metadata.freq,
trainer_kwargs={
"enable_progress_bar": False,
"enable_model_summary": False,
"max_epochs": 10,
},
)
After specifying our estimator with all the necessary hyperparameters we can train it using our training dataset train_subset by invoking the train method of the estimator. The training algorithm returns a fitted model (or a Predictor in GluonTS parlance) that can be used to obtain forecasts.
[11]:
predictor = estimator.train(dataset.train, cache_data=True)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 50: 'train_loss' reached 5.68312 (best 5.68312), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_6/checkpoints/epoch=0-step=50.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 100: 'train_loss' reached 4.86123 (best 4.86123), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_6/checkpoints/epoch=1-step=100.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 150: 'train_loss' reached 4.66699 (best 4.66699), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_6/checkpoints/epoch=2-step=150.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 3, global step 200: 'train_loss' reached 4.48419 (best 4.48419), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_6/checkpoints/epoch=3-step=200.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 4, global step 250: 'train_loss' reached 4.21752 (best 4.21752), saving model to '/home/runner/work/gluonts/gluonts/lightning_logs/version_6/checkpoints/epoch=4-step=250.ckpt' as top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 5, global step 300: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 6, global step 350: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 7, global step 400: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 8, global step 450: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:Epoch 9, global step 500: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=10` reached.
Visualize and evaluate forecasts#
With a predictor in hand, we can now predict the last window of the test dataset and evaluate our model’s performance.
GluonTS comes with the make_evaluation_predictions function that automates the process of prediction and model evaluation. Roughly, this function performs the following steps:
Removes the final window of length
prediction_lengthof the test dataset that we want to predictThe estimator uses the remaining data to predict (in the form of sample paths) the “future” window that was just removed
The forecasts are returned, together with ground truth values for the same time range (as python generator objects)
[12]:
from gluonts.evaluation import make_evaluation_predictions
forecast_it, ts_it = make_evaluation_predictions(
dataset=dataset.test,
predictor=predictor,
)
First, we can convert these generators to lists to ease the subsequent computations.
[13]:
forecasts = list(forecast_it)
tss = list(ts_it)
Forecast objects have a plot method that can summarize the forecast paths as the mean, prediction intervals, etc. The prediction intervals are shaded in different colors as a “fan chart”.
[14]:
def plot_prob_forecasts(ts_entry, forecast_entry):
plot_length = 150
prediction_intervals = (50.0, 90.0)
legend = ["observations", "median prediction"] + [
f"{k}% prediction interval" for k in prediction_intervals
][::-1]
fig, ax = plt.subplots(1, 1, figsize=(10, 7))
ts_entry[-plot_length:].plot(ax=ax) # plot the time series
forecast_entry.plot(prediction_intervals=prediction_intervals, color="g")
plt.grid(which="both")
plt.legend(legend, loc="upper left")
plt.show()
[15]:
plot_prob_forecasts(tss[0], forecasts[0])
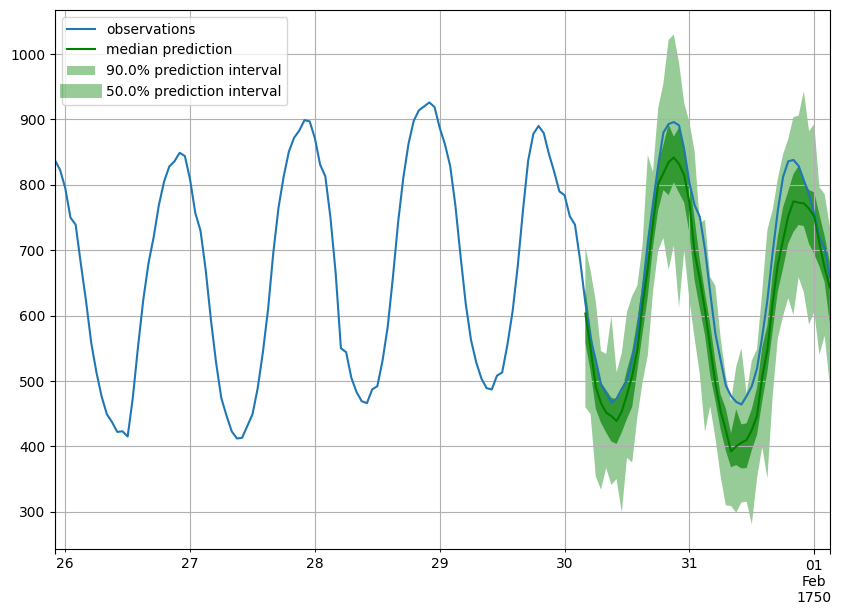
We can also evaluate the quality of our forecasts numerically. In GluonTS, the Evaluator class can compute aggregate performance metrics, as well as metrics per time series (which can be useful for analyzing performance across heterogeneous time series).
[16]:
from gluonts.evaluation import Evaluator
[17]:
evaluator = Evaluator(quantiles=[0.1, 0.5, 0.9])
agg_metrics, item_metrics = evaluator(tss, forecasts)
Running evaluation: 414it [00:00, 16994.95it/s]
Aggregate metrics aggregate both across time-steps and across time series.
[18]:
print(json.dumps(agg_metrics, indent=4))
{
"MSE": 10860944.469010107,
"abs_error": 10972103.9390831,
"abs_target_sum": 145558863.59960938,
"abs_target_mean": 7324.822041043146,
"seasonal_error": 336.9046924038305,
"MASE": 7.644149486963246,
"MAPE": 0.20824255659912325,
"sMAPE": 0.19897970717382316,
"MSIS": 45.61997211256923,
"QuantileLoss[0.1]": 5431852.512577248,
"Coverage[0.1]": 0.03884863123993559,
"QuantileLoss[0.5]": 10972103.90365696,
"Coverage[0.5]": 0.18805354267310787,
"QuantileLoss[0.9]": 6054090.311122894,
"Coverage[0.9]": 0.6543377616747181,
"RMSE": 3295.5947064240327,
"NRMSE": 0.44992147085046436,
"ND": 0.07537915361351134,
"wQuantileLoss[0.1]": 0.0373172225878234,
"wQuantileLoss[0.5]": 0.07537915337013118,
"wQuantileLoss[0.9]": 0.04159204160713949,
"mean_absolute_QuantileLoss": 7486015.5757857,
"mean_wQuantileLoss": 0.05142947252169802,
"MAE_Coverage": 0.31811258722490604,
"OWA": NaN
}
Individual metrics are aggregated only across time-steps.
[19]:
item_metrics.head()
[19]:
| item_id | forecast_start | MSE | abs_error | abs_target_sum | abs_target_mean | seasonal_error | MASE | MAPE | sMAPE | ND | MSIS | QuantileLoss[0.1] | Coverage[0.1] | QuantileLoss[0.5] | Coverage[0.5] | QuantileLoss[0.9] | Coverage[0.9] | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1750-01-30 04:00 | 3655.929362 | 2417.363281 | 31644.0 | 659.250000 | 42.371302 | 1.188581 | 0.079701 | 0.084095 | 0.076392 | 8.551633 | 1312.539789 | 0.000000 | 2417.363312 | 0.00 | 494.172815 | 0.812500 |
| 1 | 1 | 1750-01-30 04:00 | 31057.638021 | 7210.240234 | 124149.0 | 2586.437500 | 165.107988 | 0.909788 | 0.058813 | 0.056838 | 0.058077 | 9.406829 | 2565.308887 | 0.020833 | 7210.240479 | 0.75 | 4545.412085 | 1.000000 |
| 2 | 2 | 1750-01-30 04:00 | 132251.270833 | 15139.737305 | 65030.0 | 1354.791667 | 78.889053 | 3.998162 | 0.220149 | 0.253002 | 0.232812 | 60.309992 | 4280.886426 | 0.000000 | 15139.737122 | 0.00 | 17104.266089 | 0.145833 |
| 3 | 3 | 1750-01-30 04:00 | 513318.916667 | 27947.890625 | 235783.0 | 4912.145833 | 258.982249 | 2.248215 | 0.113247 | 0.121944 | 0.118532 | 15.864155 | 10284.528516 | 0.000000 | 27947.889648 | 0.25 | 17293.781934 | 0.562500 |
| 4 | 4 | 1750-01-30 04:00 | 272683.291667 | 23043.822266 | 131088.0 | 2731.000000 | 200.494083 | 2.394483 | 0.177885 | 0.197816 | 0.175789 | 13.438958 | 7717.785168 | 0.000000 | 23043.820679 | 0.00 | 16086.755859 | 0.270833 |
[20]:
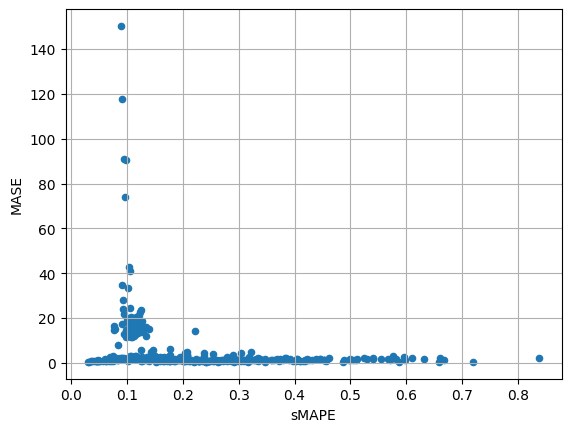
item_metrics.plot(x="sMAPE", y="MASE", kind="scatter")
plt.grid(which="both")
plt.show()