Extended Forecasting Tutorial#
[1]:
%matplotlib inline
import mxnet as mx
from mxnet import gluon
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import json
import os
from itertools import islice
from pathlib import Path
[2]:
mx.random.seed(0)
np.random.seed(0)
Datasets#
The first requirement to use GluonTS is to have an appropriate dataset. GluonTS offers three different options to practitioners that want to experiment with the various modules:
Use an available dataset provided by GluonTS
Create an artificial dataset using GluonTS
Convert your dataset to a GluonTS friendly format
In general, a dataset should satisfy some minimum format requirements to be compatible with GluonTS. In particular, it should be an iterable collection of data entries (time series), and each entry should have at least a target field, which contains the actual values of the time series, and a start field, which denotes the starting date of the time series. There are many more optional fields that we will go through in this tutorial.
The datasets provided by GluonTS come in the appropriate format and they can be used without any post processing. However, a custom dataset needs to be converted. Fortunately this is an easy task.
Available datasets in GluonTS#
GluonTS comes with a number of available datasets.
[3]:
from gluonts.dataset.repository import get_dataset, dataset_names
from gluonts.dataset.util import to_pandas
[4]:
print(f"Available datasets: {dataset_names}")
Available datasets: ['constant', 'exchange_rate', 'solar-energy', 'electricity', 'traffic', 'exchange_rate_nips', 'electricity_nips', 'traffic_nips', 'solar_nips', 'wiki2000_nips', 'wiki-rolling_nips', 'taxi_30min', 'kaggle_web_traffic_with_missing', 'kaggle_web_traffic_without_missing', 'kaggle_web_traffic_weekly', 'm1_yearly', 'm1_quarterly', 'm1_monthly', 'nn5_daily_with_missing', 'nn5_daily_without_missing', 'nn5_weekly', 'tourism_monthly', 'tourism_quarterly', 'tourism_yearly', 'cif_2016', 'london_smart_meters_without_missing', 'wind_farms_without_missing', 'car_parts_without_missing', 'dominick', 'fred_md', 'pedestrian_counts', 'hospital', 'covid_deaths', 'kdd_cup_2018_without_missing', 'weather', 'm3_monthly', 'm3_quarterly', 'm3_yearly', 'm3_other', 'm4_hourly', 'm4_daily', 'm4_weekly', 'm4_monthly', 'm4_quarterly', 'm4_yearly', 'm5', 'uber_tlc_daily', 'uber_tlc_hourly', 'airpassengers', 'australian_electricity_demand', 'electricity_hourly', 'electricity_weekly', 'rideshare_without_missing', 'saugeenday', 'solar_10_minutes', 'solar_weekly', 'sunspot_without_missing', 'temperature_rain_without_missing', 'vehicle_trips_without_missing', 'ercot', 'ett_small_15min', 'ett_small_1h']
To download one of the built-in datasets, simply call get_dataset with one of the above names. GluonTS can re-use the saved dataset so that it does not need to be downloaded again the next time around.
[5]:
dataset = get_dataset("m4_hourly")
What is in a dataset?#
In general, the datasets provided by GluonTS are objects that consists of three main members:
dataset.trainis an iterable collection of data entries used for training. Each entry corresponds to one time series.dataset.testis an iterable collection of data entries used for inference. The test dataset is an extended version of the train dataset that contains a window in the end of each time series that was not seen during training. This window has length equal to the recommended prediction length.dataset.metadatacontains metadata of the dataset such as the frequency of the time series, a recommended prediction horizon, associated features, etc.
First, let’s see what the first entry of the train dataset contains. We should expect at least a target and a start field in each entry, and the target of the test entry to have an additional window equal to prediction_length.
[6]:
# get the first time series in the training set
train_entry = next(iter(dataset.train))
train_entry.keys()
[6]:
dict_keys(['target', 'start', 'feat_static_cat', 'item_id'])
We observe that apart from the required fields there is one more feat_static_cat field (we can safely ignore the source field). This shows that the dataset has some features apart from the values of the time series. For now, we will ignore this field too. We will explain it in detail later with all the other optional fields.
We can similarly examine the first entry of the test dataset. We should expect exactly the same fields as in the train dataset.
[7]:
# get the first time series in the test set
test_entry = next(iter(dataset.test))
test_entry.keys()
[7]:
dict_keys(['target', 'start', 'feat_static_cat', 'item_id'])
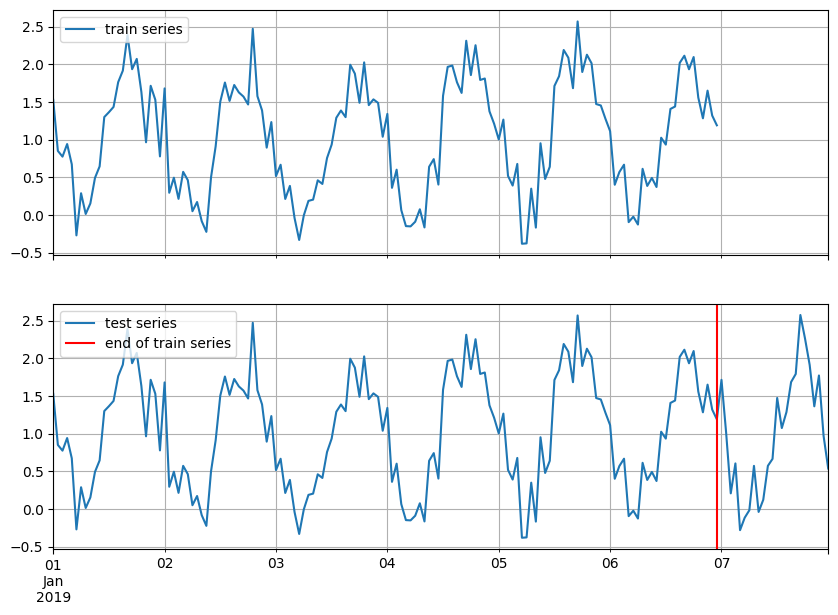
Moreover, we should expect that the target will have an additional window in the end with length equal to prediction_length. To better understand what this means we can visualize both the train and test time series.
[8]:
test_series = to_pandas(test_entry)
train_series = to_pandas(train_entry)
fig, ax = plt.subplots(2, 1, sharex=True, sharey=True, figsize=(10, 7))
train_series.plot(ax=ax[0])
ax[0].grid(which="both")
ax[0].legend(["train series"], loc="upper left")
test_series.plot(ax=ax[1])
ax[1].axvline(train_series.index[-1], color="r") # end of train dataset
ax[1].grid(which="both")
ax[1].legend(["test series", "end of train series"], loc="upper left")
plt.show()

[9]:
print(
f"Length of forecasting window in test dataset: {len(test_series) - len(train_series)}"
)
print(f"Recommended prediction horizon: {dataset.metadata.prediction_length}")
print(f"Frequency of the time series: {dataset.metadata.freq}")
Length of forecasting window in test dataset: 48
Recommended prediction horizon: 48
Frequency of the time series: H
Create artificial datasets#
We can easily create a complex artificial time series dataset using the ComplexSeasonalTimeSeries module.
[10]:
from gluonts.dataset.artificial import ComplexSeasonalTimeSeries
from gluonts.dataset.common import ListDataset
[11]:
artificial_dataset = ComplexSeasonalTimeSeries(
num_series=10,
prediction_length=21,
freq_str="H",
length_low=30,
length_high=200,
min_val=-10000,
max_val=10000,
is_integer=False,
proportion_missing_values=0,
is_noise=True,
is_scale=True,
percentage_unique_timestamps=1,
is_out_of_bounds_date=True,
)
We can access some important metadata of the artificial dataset as follows:
[12]:
print(f"prediction length: {artificial_dataset.metadata.prediction_length}")
print(f"frequency: {artificial_dataset.metadata.freq}")
prediction length: 21
frequency: H
The artificial dataset that we created is a list of dictionaries. Each dictionary corresponds to a time series and it should contain the required fields.
[13]:
print(f"type of train dataset: {type(artificial_dataset.train)}")
print(f"train dataset fields: {artificial_dataset.train[0].keys()}")
print(f"type of test dataset: {type(artificial_dataset.test)}")
print(f"test dataset fields: {artificial_dataset.test[0].keys()}")
type of train dataset: <class 'list'>
train dataset fields: dict_keys(['start', 'target', 'item_id'])
type of test dataset: <class 'list'>
test dataset fields: dict_keys(['start', 'target', 'item_id'])
In order to use the artificially created datasets (list of dictionaries) we need to convert them to ListDataset objects.
[14]:
train_ds = ListDataset(artificial_dataset.train, freq=artificial_dataset.metadata.freq)
[15]:
test_ds = ListDataset(artificial_dataset.test, freq=artificial_dataset.metadata.freq)
[16]:
train_entry = next(iter(train_ds))
train_entry.keys()
[16]:
dict_keys(['start', 'target', 'item_id'])
[17]:
test_entry = next(iter(test_ds))
test_entry.keys()
[17]:
dict_keys(['start', 'target', 'item_id'])
[18]:
test_series = to_pandas(test_entry)
train_series = to_pandas(train_entry)
fig, ax = plt.subplots(2, 1, sharex=True, sharey=True, figsize=(10, 7))
train_series.plot(ax=ax[0])
ax[0].grid(which="both")
ax[0].legend(["train series"], loc="upper left")
test_series.plot(ax=ax[1])
ax[1].axvline(train_series.index[-1], color="r") # end of train dataset
ax[1].grid(which="both")
ax[1].legend(["test series", "end of train series"], loc="upper left")
plt.show()

Use your time series and features#
Now, we will see how we can convert any custom dataset with any associated features to an appropriate format for GluonTS.
As already mentioned a dataset is required to have at least the target and the start fields. However, it may have more. Let’s see what are all the available fields:
[19]:
from gluonts.dataset.field_names import FieldName
[20]:
[
f"FieldName.{k} = '{v}'"
for k, v in FieldName.__dict__.items()
if not k.startswith("_")
]
[20]:
["FieldName.ITEM_ID = 'item_id'",
"FieldName.INFO = 'info'",
"FieldName.START = 'start'",
"FieldName.TARGET = 'target'",
"FieldName.FEAT_STATIC_CAT = 'feat_static_cat'",
"FieldName.FEAT_STATIC_REAL = 'feat_static_real'",
"FieldName.FEAT_DYNAMIC_CAT = 'feat_dynamic_cat'",
"FieldName.FEAT_DYNAMIC_REAL = 'feat_dynamic_real'",
"FieldName.PAST_FEAT_DYNAMIC_CAT = 'past_feat_dynamic_cat'",
"FieldName.PAST_FEAT_DYNAMIC_REAL = 'past_feat_dynamic_real'",
"FieldName.FEAT_DYNAMIC_REAL_LEGACY = 'dynamic_feat'",
"FieldName.FEAT_DYNAMIC = 'feat_dynamic'",
"FieldName.PAST_FEAT_DYNAMIC = 'past_feat_dynamic'",
"FieldName.FEAT_TIME = 'time_feat'",
"FieldName.FEAT_CONST = 'feat_dynamic_const'",
"FieldName.FEAT_AGE = 'feat_dynamic_age'",
"FieldName.OBSERVED_VALUES = 'observed_values'",
"FieldName.IS_PAD = 'is_pad'",
"FieldName.FORECAST_START = 'forecast_start'",
"FieldName.TARGET_DIM_INDICATOR = 'target_dimension_indicator'"]
The fields are split into three categories: the required ones, the optional ones, and the ones that can be added by the Transformation (explained in a while).
Required:
start: start date of the time seriestarget: values of the time series
Optional:
feat_static_cat: static (over time) categorical features, list with dimension equal to the number of featuresfeat_static_real: static (over time) real features, list with dimension equal to the number of featuresfeat_dynamic_cat: dynamic (over time) categorical features, array with shape equal to (number of features, target length)feat_dynamic_real: dynamic (over time) real features, array with shape equal to (number of features, target length)
Added by Transformation:
time_feat: time related features such as the month or the dayfeat_dynamic_const: expands a constant value feature along the time axisfeat_dynamic_age: age feature, i.e., a feature that its value is small for distant past timestamps and it monotonically increases the more we approach the current timestampobserved_values: indicator for observed values, i.e., a feature that equals to 1 if the value is observed and 0 if the value is missingis_pad: indicator for each time step that shows if it is padded (if the length is not enough)forecast_start: forecast start date
As a simple example, we can create a custom dataset to see how we can use some of these fields. The dataset consists of a target, a real dynamic feature (which in this example we set to be the target value one period earlier), and a static categorical feature that indicates the sinusoid type (different phase) that we used to create the target.
[21]:
def create_dataset(num_series, num_steps, period=24, mu=1, sigma=0.3):
# create target: noise + pattern
# noise
noise = np.random.normal(mu, sigma, size=(num_series, num_steps))
# pattern - sinusoid with different phase
sin_minusPi_Pi = np.sin(
np.tile(np.linspace(-np.pi, np.pi, period), int(num_steps / period))
)
sin_Zero_2Pi = np.sin(
np.tile(np.linspace(0, 2 * np.pi, 24), int(num_steps / period))
)
pattern = np.concatenate(
(
np.tile(sin_minusPi_Pi.reshape(1, -1), (int(np.ceil(num_series / 2)), 1)),
np.tile(sin_Zero_2Pi.reshape(1, -1), (int(np.floor(num_series / 2)), 1)),
),
axis=0,
)
target = noise + pattern
# create time features: use target one period earlier, append with zeros
feat_dynamic_real = np.concatenate(
(np.zeros((num_series, period)), target[:, :-period]), axis=1
)
# create categorical static feats: use the sinusoid type as a categorical feature
feat_static_cat = np.concatenate(
(
np.zeros(int(np.ceil(num_series / 2))),
np.ones(int(np.floor(num_series / 2))),
),
axis=0,
)
return target, feat_dynamic_real, feat_static_cat
[22]:
# define the parameters of the dataset
custom_ds_metadata = {
"num_series": 100,
"num_steps": 24 * 7,
"prediction_length": 24,
"freq": "1H",
"start": [pd.Period("01-01-2019", freq="1H") for _ in range(100)],
}
[23]:
data_out = create_dataset(
custom_ds_metadata["num_series"],
custom_ds_metadata["num_steps"],
custom_ds_metadata["prediction_length"],
)
target, feat_dynamic_real, feat_static_cat = data_out
We can easily create the train and test datasets by simply filling in the correct fields. Remember that for the train dataset we need to cut the last window.
[24]:
train_ds = ListDataset(
[
{
FieldName.TARGET: target,
FieldName.START: start,
FieldName.FEAT_DYNAMIC_REAL: [fdr],
FieldName.FEAT_STATIC_CAT: [fsc],
}
for (target, start, fdr, fsc) in zip(
target[:, : -custom_ds_metadata["prediction_length"]],
custom_ds_metadata["start"],
feat_dynamic_real[:, : -custom_ds_metadata["prediction_length"]],
feat_static_cat,
)
],
freq=custom_ds_metadata["freq"],
)
[25]:
test_ds = ListDataset(
[
{
FieldName.TARGET: target,
FieldName.START: start,
FieldName.FEAT_DYNAMIC_REAL: [fdr],
FieldName.FEAT_STATIC_CAT: [fsc],
}
for (target, start, fdr, fsc) in zip(
target, custom_ds_metadata["start"], feat_dynamic_real, feat_static_cat
)
],
freq=custom_ds_metadata["freq"],
)
Now, we can examine each entry of the train and test datasets. We should expect that they have the following fields: target, start, feat_dynamic_real and feat_static_cat.
[26]:
train_entry = next(iter(train_ds))
train_entry.keys()
[26]:
dict_keys(['target', 'start', 'feat_dynamic_real', 'feat_static_cat'])
[27]:
test_entry = next(iter(test_ds))
test_entry.keys()
[27]:
dict_keys(['target', 'start', 'feat_dynamic_real', 'feat_static_cat'])
[28]:
test_series = to_pandas(test_entry)
train_series = to_pandas(train_entry)
fig, ax = plt.subplots(2, 1, sharex=True, sharey=True, figsize=(10, 7))
train_series.plot(ax=ax[0])
ax[0].grid(which="both")
ax[0].legend(["train series"], loc="upper left")
test_series.plot(ax=ax[1])
ax[1].axvline(train_series.index[-1], color="r") # end of train dataset
ax[1].grid(which="both")
ax[1].legend(["test series", "end of train series"], loc="upper left")
plt.show()
For the rest of the tutorial we will use the custom dataset
Transformations#
Define a transformation#
The primary use case for a Transformation is for feature processing, e.g., adding a holiday feature and for defining the way the dataset will be split into appropriate windows during training and inference.
In general, it gets an iterable collection of entries of a dataset and transform it to another iterable collection that can possibly contain more fields. The transformation is done by defining a set of “actions” to the raw dataset depending on what is useful to our model. This actions usually create some additional features or transform an existing feature. As an example, in the following we add the following transformations:
AddObservedValuesIndicator: Creates theobserved_valuesfield in the dataset, i.e., adds a feature that equals to 1 if the value is observed and 0 if the value is missingAddAgeFeature: Creates thefeat_dynamic_agefield in the dataset, i.e., adds a feature that its value is small for distant past timestamps and it monotonically increases the more we approach the current timestamp
One more transformation that can be used is the InstanceSplitter, which is used to define how the datasets are going to be split in example windows during training, validation, or at prediction time. The InstanceSplitter is configured as follows (skipping the obvious fields):
is_pad_field: indicator if the time series is padded (if the length is not enough)train_sampler: defines how the training windows are cut/sampledtime_series_fields: contains the time dependent features that need to be split in the same manner as the target
[29]:
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
SetFieldIfNotPresent,
)
[30]:
def create_transformation(freq, context_length, prediction_length):
return Chain(
[
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=prediction_length,
log_scale=True,
),
InstanceSplitter(
target_field=FieldName.TARGET,
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=ExpectedNumInstanceSampler(
num_instances=1,
min_future=prediction_length,
),
past_length=context_length,
future_length=prediction_length,
time_series_fields=[
FieldName.FEAT_AGE,
FieldName.FEAT_DYNAMIC_REAL,
FieldName.OBSERVED_VALUES,
],
),
]
)
Transform a dataset#
Now, we can create a transformation object by applying the above transformation to the custom dataset we have created.
[31]:
transformation = create_transformation(
custom_ds_metadata["freq"],
2 * custom_ds_metadata["prediction_length"], # can be any appropriate value
custom_ds_metadata["prediction_length"],
)
[32]:
train_tf = transformation(iter(train_ds), is_train=True)
[33]:
type(train_tf)
[33]:
generator
As expected, the output is another iterable object. We can easily examine what is contained in an entry of the transformed dataset. The InstanceSplitter iterates over the transformed dataset and cuts windows by selecting randomly a time series and a starting point on that time series (this “randomness” is defined by the instance_sampler).
[34]:
train_tf_entry = next(iter(train_tf))
[k for k in train_tf_entry.keys()]
[34]:
['start',
'feat_static_cat',
'past_feat_dynamic_age',
'future_feat_dynamic_age',
'past_feat_dynamic_real',
'future_feat_dynamic_real',
'past_observed_values',
'future_observed_values',
'past_target',
'future_target',
'past_is_pad',
'forecast_start']
The transformer has done what we asked. In particular it has added:
a field for observed values (
observed_values)a field for the age feature (
feat_dynamic_age)some extra useful fields (
past_is_pad,forecast_start)
It has done one more important thing: it has split the window into past and future and has added the corresponding prefixes to all time dependent fields. This way we can easily use e.g., the past_target field as input and the future_target field to calculate the error of our predictions. Of course, the length of the past is equal to the context_length and of the future equal to the prediction_length.
[35]:
print(f"past target shape: {train_tf_entry['past_target'].shape}")
print(f"future target shape: {train_tf_entry['future_target'].shape}")
print(f"past observed values shape: {train_tf_entry['past_observed_values'].shape}")
print(f"future observed values shape: {train_tf_entry['future_observed_values'].shape}")
print(f"past age feature shape: {train_tf_entry['past_feat_dynamic_age'].shape}")
print(f"future age feature shape: {train_tf_entry['future_feat_dynamic_age'].shape}")
print(train_tf_entry["feat_static_cat"])
past target shape: (48,)
future target shape: (24,)
past observed values shape: (48,)
future observed values shape: (24,)
past age feature shape: (48, 1)
future age feature shape: (24, 1)
[0]
Just for comparison, let’s see again what were the fields in the original dataset before the transformation:
[36]:
[k for k in next(iter(train_ds)).keys()]
[36]:
['target', 'start', 'feat_dynamic_real', 'feat_static_cat']
Now, we can move on and see how the test dataset is split. As we saw, the transformation splits the windows into past and future. However, during inference (is_train=False in the transformation), the splitter always cuts the last window (of length context_length) of the dataset so it can be used to predict the subsequent unknown values of length prediction_length.
So, how is the test dataset split in past and future since we do not know the future target? And what about the time dependent features?
[37]:
test_tf = transformation(iter(test_ds), is_train=False)
[38]:
test_tf_entry = next(iter(test_tf))
[k for k in test_tf_entry.keys()]
[38]:
['start',
'feat_static_cat',
'past_feat_dynamic_age',
'future_feat_dynamic_age',
'past_feat_dynamic_real',
'future_feat_dynamic_real',
'past_observed_values',
'future_observed_values',
'past_target',
'future_target',
'past_is_pad',
'forecast_start']
[39]:
print(f"past target shape: {test_tf_entry['past_target'].shape}")
print(f"future target shape: {test_tf_entry['future_target'].shape}")
print(f"past observed values shape: {test_tf_entry['past_observed_values'].shape}")
print(f"future observed values shape: {test_tf_entry['future_observed_values'].shape}")
print(f"past age feature shape: {test_tf_entry['past_feat_dynamic_age'].shape}")
print(f"future age feature shape: {test_tf_entry['future_feat_dynamic_age'].shape}")
print(test_tf_entry["feat_static_cat"])
past target shape: (48,)
future target shape: (24,)
past observed values shape: (48,)
future observed values shape: (24,)
past age feature shape: (48, 1)
future age feature shape: (24, 1)
[0]
The future target is empty but not the features - we always assume that we know the future features!
All the things we did manually here are done by an internal block called DataLoader. It gets as an input the raw dataset (in appropriate format) and the transformation object and it outputs the transformed iterable dataset batch by batch. The only thing that we need to worry about is setting the transformation fields correctly!
Training an existing model#
GluonTS comes with a number of pre-built models. All the user needs to do is configure some hyperparameters. The existing models focus on (but are not limited to) probabilistic forecasting. Probabilistic forecasts are predictions in the form of a probability distribution, rather than simply a single point estimate. Having estimated the future distribution of each time step in the forecasting horizon, we can draw a sample from the distribution at each time step and thus create a “sample path” that can be seen as a possible realization of the future. In practice we draw multiple samples and create multiple sample paths which can be used for visualization, evaluation of the model, to derive statistics, etc.
Configuring an estimator#
We will begin with GluonTS’s pre-built feedforward neural network estimator, a simple but powerful forecasting model. We will use this model to demonstrate the process of training a model, producing forecasts, and evaluating the results.
GluonTS’s built-in feedforward neural network (SimpleFeedForwardEstimator) accepts an input window of length context_length and predicts the distribution of the values of the subsequent prediction_length values. In GluonTS parlance, the feedforward neural network model is an example of Estimator. In GluonTS, Estimator objects represent a forecasting model as well as details such as its coefficients, weights, etc.
In general, each estimator (pre-built or custom) is configured by a number of hyperparameters that can be either common (but not binding) among all estimators (e.g., the prediction_length) or specific for the particular estimator (e.g., number of layers for a neural network or the stride in a CNN).
Finally, each estimator is configured by a Trainer, which defines how the model will be trained i.e., the number of epochs, the learning rate, etc.
[40]:
from gluonts.mx import SimpleFeedForwardEstimator, Trainer
[41]:
estimator = SimpleFeedForwardEstimator(
num_hidden_dimensions=[10],
prediction_length=custom_ds_metadata["prediction_length"],
context_length=2 * custom_ds_metadata["prediction_length"],
trainer=Trainer(
ctx="cpu",
epochs=5,
learning_rate=1e-3,
hybridize=False,
num_batches_per_epoch=100,
),
)
Getting a predictor#
After specifying our estimator with all the necessary hyperparameters we can train it using our training dataset dataset.train by invoking the train method of the estimator. The training algorithm returns a fitted model (or a Predictor in GluonTS parlance) that can be used to construct forecasts.
We should emphasize here that a single model, as the one defined above, is trained over all the time series contained in the training dataset train_ds. This results in a global model, suitable for prediction for all the time series in train_ds and possibly for other unseen related time series.
[42]:
predictor = estimator.train(train_ds)
100%|██████████| 100/100 [00:00<00:00, 121.53it/s, epoch=1/5, avg_epoch_loss=1.28]
100%|██████████| 100/100 [00:00<00:00, 124.61it/s, epoch=2/5, avg_epoch_loss=0.735]
100%|██████████| 100/100 [00:00<00:00, 122.58it/s, epoch=3/5, avg_epoch_loss=0.677]
100%|██████████| 100/100 [00:00<00:00, 124.03it/s, epoch=4/5, avg_epoch_loss=0.644]
100%|██████████| 100/100 [00:00<00:00, 136.28it/s, epoch=5/5, avg_epoch_loss=0.605]
Saving/Loading an existing model#
A fitted model, i.e., a Predictor, can be saved and loaded back easily:
[43]:
# save the trained model in tmp/
from pathlib import Path
predictor.serialize(Path("/tmp/"))
WARNING:root:Serializing RepresentableBlockPredictor instances does not save the prediction network structure in a backwards-compatible manner. Be careful not to use this method in production.
[44]:
# loads it back
from gluonts.model.predictor import Predictor
predictor_deserialized = Predictor.deserialize(Path("/tmp/"))
Evaluation#
Getting the forecasts#
With a predictor in hand, we can now predict the last window of the dataset.test and evaluate our model’s performance.
GluonTS comes with the make_evaluation_predictions function that automates the process of prediction and model evaluation. Roughly, this function performs the following steps:
Removes the final window of length
prediction_lengthof thedataset.testthat we want to predictThe estimator uses the remaining data to predict (in the form of sample paths) the “future” window that was just removed
The module outputs the forecast sample paths and the
dataset.test(as python generator objects)
[45]:
from gluonts.evaluation import make_evaluation_predictions
[46]:
forecast_it, ts_it = make_evaluation_predictions(
dataset=test_ds, # test dataset
predictor=predictor, # predictor
num_samples=100, # number of sample paths we want for evaluation
)
First, we can convert these generators to lists to ease the subsequent computations.
[47]:
forecasts = list(forecast_it)
tss = list(ts_it)
We can examine the first element of these lists (that corresponds to the first time series of the dataset). Let’s start with the list containing the time series, i.e., tss. We expect the first entry of tss to contain the (target of the) first time series of test_ds.
[48]:
# first entry of the time series list
ts_entry = tss[0]
[49]:
# first 5 values of the time series (convert from pandas to numpy)
np.array(ts_entry[:5]).reshape(
-1,
)
[49]:
array([1.5292157 , 0.85025036, 0.7740374 , 0.941432 , 0.6723822 ],
dtype=float32)
[50]:
# first entry of test_ds
test_ds_entry = next(iter(test_ds))
[51]:
# first 5 values
test_ds_entry["target"][:5]
[51]:
array([1.5292157 , 0.85025036, 0.7740374 , 0.941432 , 0.6723822 ],
dtype=float32)
The entries in the forecast list are a bit more complex. They are objects that contain all the sample paths in the form of numpy.ndarray with dimension (num_samples, prediction_length), the start date of the forecast, the frequency of the time series, etc. We can access all these information by simply invoking the corresponding attribute of the forecast object.
[52]:
# first entry of the forecast list
forecast_entry = forecasts[0]
[53]:
print(f"Number of sample paths: {forecast_entry.num_samples}")
print(f"Dimension of samples: {forecast_entry.samples.shape}")
print(f"Start date of the forecast window: {forecast_entry.start_date}")
print(f"Frequency of the time series: {forecast_entry.freq}")
Number of sample paths: 100
Dimension of samples: (100, 24)
Start date of the forecast window: 2019-01-07 00:00
Frequency of the time series: <Hour>
We can also do calculations to summarize the sample paths, such as computing the mean or a quantile for each of the 24 time steps in the forecast window.
[54]:
print(f"Mean of the future window:\n {forecast_entry.mean}")
print(f"0.5-quantile (median) of the future window:\n {forecast_entry.quantile(0.5)}")
Mean of the future window:
[ 0.90765196 0.5002642 0.58970827 0.39372978 0.09580009 0.05871432
-0.09855336 0.21287599 0.06411848 0.36389527 0.6184984 0.82686234
1.1362944 1.4422988 1.5806047 1.885066 1.6728904 1.8457131
2.0097268 1.7956799 1.6775795 1.587245 1.2241242 1.0475011 ]
0.5-quantile (median) of the future window:
[ 9.2138731e-01 5.3099197e-01 5.4954773e-01 3.5585621e-01
1.3284978e-01 5.4421678e-02 -5.3116154e-02 1.7734313e-01
-1.0389383e-03 3.8981181e-01 6.4071041e-01 8.7102258e-01
1.1050647e+00 1.2608457e+00 1.5636476e+00 1.9202025e+00
1.7487336e+00 1.8408449e+00 2.0478199e+00 1.7664530e+00
1.7128807e+00 1.6053847e+00 1.2772603e+00 1.0452789e+00]
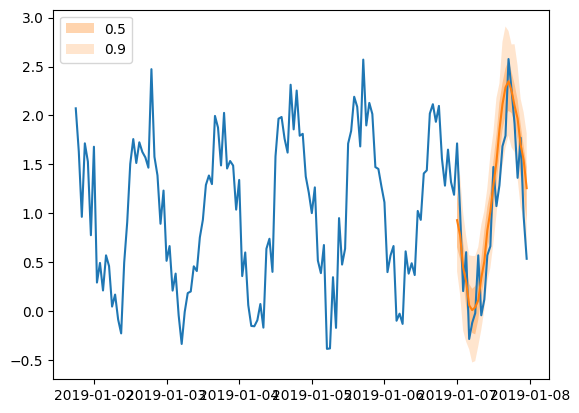
Forecast objects have a plot method that can summarize the forecast paths as the mean, prediction intervals, etc. The prediction intervals are shaded in different colors as a “fan chart”.
[55]:
plt.plot(ts_entry[-150:].to_timestamp())
forecast_entry.plot(show_label=True)
plt.legend()
[55]:
<matplotlib.legend.Legend at 0x7f24980497f0>
Compute metrics#
We can also evaluate the quality of our forecasts numerically. In GluonTS, the Evaluator class can compute aggregate performance metrics, as well as metrics per time series (which can be useful for analyzing performance across heterogeneous time series).
[56]:
from gluonts.evaluation import Evaluator
[57]:
evaluator = Evaluator(quantiles=[0.1, 0.5, 0.9])
agg_metrics, item_metrics = evaluator(tss, forecasts)
Running evaluation: 100it [00:00, 2858.91it/s]
Aggregate metrics aggregate both across time-steps and across time series.
[58]:
print(json.dumps(agg_metrics, indent=4))
{
"MSE": 0.11030595362186432,
"abs_error": 631.219958782196,
"abs_target_sum": 2505.765546798706,
"abs_target_mean": 1.044068977832794,
"seasonal_error": 0.3378558193842571,
"MASE": 0.7856021114063411,
"MAPE": 2.2423562081654866,
"sMAPE": 0.5366955331961314,
"MSIS": 5.561884554254895,
"num_masked_target_values": 0.0,
"QuantileLoss[0.1]": 274.70157045163216,
"Coverage[0.1]": 0.09208333333333334,
"QuantileLoss[0.5]": 631.2199574247934,
"Coverage[0.5]": 0.4904166666666667,
"QuantileLoss[0.9]": 295.76119372472164,
"Coverage[0.9]": 0.8820833333333331,
"RMSE": 0.332123401195797,
"NRMSE": 0.3181048457978281,
"ND": 0.2519070308028716,
"wQuantileLoss[0.1]": 0.10962780249037385,
"wQuantileLoss[0.5]": 0.25190703026115985,
"wQuantileLoss[0.9]": 0.11803226926101591,
"mean_absolute_QuantileLoss": 400.5609072003824,
"mean_wQuantileLoss": 0.15985570067084987,
"MAE_Coverage": 0.39402777777777764,
"OWA": NaN
}
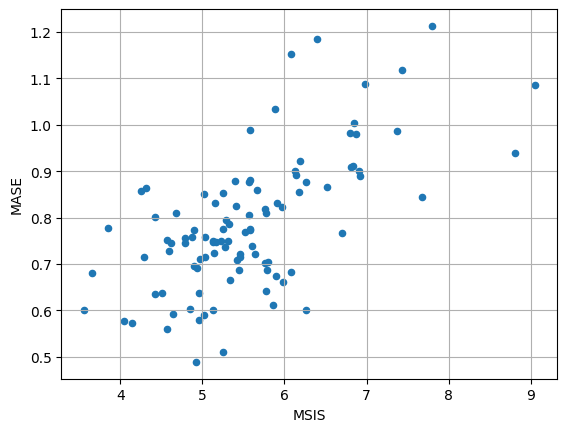
Individual metrics are aggregated only across time-steps.
[59]:
item_metrics.head()
[59]:
| item_id | forecast_start | MSE | abs_error | abs_target_sum | abs_target_mean | seasonal_error | MASE | MAPE | sMAPE | num_masked_target_values | ND | MSIS | QuantileLoss[0.1] | Coverage[0.1] | QuantileLoss[0.5] | Coverage[0.5] | QuantileLoss[0.9] | Coverage[0.9] | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | 2019-01-07 00:00 | 0.123998 | 7.011340 | 24.638548 | 1.026606 | 0.351642 | 0.830787 | 0.627694 | 0.607183 | 0.0 | 0.284568 | 5.906248 | 2.286915 | 0.083333 | 7.011340 | 0.541667 | 3.406847 | 0.875000 |
| 1 | None | 2019-01-07 00:00 | 0.109331 | 5.898170 | 22.178631 | 0.924110 | 0.340241 | 0.722302 | 1.439482 | 0.555920 | 0.0 | 0.265939 | 5.646115 | 2.598318 | 0.083333 | 5.898170 | 0.666667 | 3.049512 | 0.916667 |
| 2 | None | 2019-01-07 00:00 | 0.150442 | 6.913772 | 26.601139 | 1.108381 | 0.323560 | 0.890326 | 0.419949 | 0.536978 | 0.0 | 0.259905 | 6.923015 | 3.400284 | 0.125000 | 6.913772 | 0.500000 | 3.971697 | 0.791667 |
| 3 | None | 2019-01-07 00:00 | 0.124376 | 6.302595 | 22.502333 | 0.937597 | 0.311026 | 0.844329 | 1.099858 | 0.609671 | 0.0 | 0.280086 | 7.677102 | 3.067686 | 0.208333 | 6.302595 | 0.583333 | 3.414130 | 0.958333 |
| 4 | None | 2019-01-07 00:00 | 0.073736 | 4.519842 | 25.864388 | 1.077683 | 0.313119 | 0.601453 | 0.920273 | 0.425719 | 0.0 | 0.174752 | 6.257542 | 2.332712 | 0.041667 | 4.519842 | 0.500000 | 2.810995 | 0.916667 |
[60]:
item_metrics.plot(x="MSIS", y="MASE", kind="scatter")
plt.grid(which="both")
plt.show()
Create your own model#
For creating our own forecast model we need to:
Define the training and prediction network
Define a new estimator that specifies any data processing and uses the networks
The training and prediction networks can be arbitrarily complex but they should follow some basic rules:
Both should have a
hybrid_forwardmethod that defines what should happen when the network is calledThe training network’s
hybrid_forwardshould return a loss based on the prediction and the true valuesThe prediction network’s
hybrid_forwardshould return the predictions
The estimator should also include the following methods:
create_transformation, defining all the data pre-processing transformations (like adding features)create_training_data_loader, constructing the data loader that gives batches to be used in training, out of a given datasetcreate_training_network, returning the training network configured with any necessary hyperparameterscreate_predictor, creating the prediction network, and returning aPredictorobject
If a validation dataset is to be accepted, for some validation metric to be computed, then also the following should be defined:
create_validation_data_loader
A Predictor defines the predictor.predict method of a given predictor. This method takes the test dataset, it passes it through the prediction network to take the predictions, and yields the predictions. You can think of the Predictor object as a wrapper of the prediction network that defines its predict method.
In this section, we will start simple by creating a feedforward network that is restricted to point forecasts. Then, we will add complexity to the network by expanding it to probabilistic forecasting, considering features and scaling of the time series, and in the end we will replace it with an RNN.
We need to emphasize that the way the following models are implemented and all the design choices that are made are neither binding nor necessarily optimal. Their sole purpose is to provide guidelines and hints on how to build a model.
Point forecasts with a simple feedforward network#
We can create a simple training network that defines a neural network that takes as input a window of length context_length and predicts the subsequent window of dimension prediction_length (thus, the output dimension of the network is prediction_length). The hybrid_forward method of the training network returns the mean of the L1 loss.
The prediction network is (and should be) identical to the training network (by inheriting the class) and its hybrid_forward method returns the predictions.
[61]:
class MyNetwork(gluon.HybridBlock):
def __init__(self, prediction_length, num_cells, **kwargs):
super().__init__(**kwargs)
self.prediction_length = prediction_length
self.num_cells = num_cells
with self.name_scope():
# Set up a 3 layer neural network that directly predicts the target values
self.nn = mx.gluon.nn.HybridSequential()
self.nn.add(mx.gluon.nn.Dense(units=self.num_cells, activation="relu"))
self.nn.add(mx.gluon.nn.Dense(units=self.num_cells, activation="relu"))
self.nn.add(
mx.gluon.nn.Dense(units=self.prediction_length, activation="softrelu")
)
class MyTrainNetwork(MyNetwork):
def hybrid_forward(self, F, past_target, future_target):
prediction = self.nn(past_target)
# calculate L1 loss with the future_target to learn the median
return (prediction - future_target).abs().mean(axis=-1)
class MyPredNetwork(MyTrainNetwork):
# The prediction network only receives past_target and returns predictions
def hybrid_forward(self, F, past_target):
prediction = self.nn(past_target)
return prediction.expand_dims(axis=1)
The estimator class is configured by a few hyperparameters and implements the required methods.
[62]:
from functools import partial
from mxnet.gluon import HybridBlock
from gluonts.core.component import validated
from gluonts.dataset.loader import TrainDataLoader
from gluonts.model.predictor import Predictor
from gluonts.mx import (
batchify,
copy_parameters,
get_hybrid_forward_input_names,
GluonEstimator,
RepresentableBlockPredictor,
Trainer,
)
from gluonts.transform import (
ExpectedNumInstanceSampler,
Transformation,
InstanceSplitter,
TestSplitSampler,
SelectFields,
Chain,
)
[63]:
class MyEstimator(GluonEstimator):
@validated()
def __init__(
self,
prediction_length: int,
context_length: int,
num_cells: int,
batch_size: int = 32,
trainer: Trainer = Trainer(),
) -> None:
super().__init__(trainer=trainer, batch_size=batch_size)
self.prediction_length = prediction_length
self.context_length = context_length
self.num_cells = num_cells
def create_transformation(self):
return Chain([])
def create_training_data_loader(self, dataset, **kwargs):
instance_splitter = InstanceSplitter(
target_field=FieldName.TARGET,
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=ExpectedNumInstanceSampler(
num_instances=1, min_future=self.prediction_length
),
past_length=self.context_length,
future_length=self.prediction_length,
)
input_names = get_hybrid_forward_input_names(MyTrainNetwork)
return TrainDataLoader(
dataset=dataset,
transform=instance_splitter + SelectFields(input_names),
batch_size=self.batch_size,
stack_fn=partial(batchify, ctx=self.trainer.ctx, dtype=self.dtype),
**kwargs,
)
def create_training_network(self) -> MyTrainNetwork:
return MyTrainNetwork(
prediction_length=self.prediction_length, num_cells=self.num_cells
)
def create_predictor(
self, transformation: Transformation, trained_network: HybridBlock
) -> Predictor:
prediction_splitter = InstanceSplitter(
target_field=FieldName.TARGET,
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=TestSplitSampler(),
past_length=self.context_length,
future_length=self.prediction_length,
)
prediction_network = MyPredNetwork(
prediction_length=self.prediction_length, num_cells=self.num_cells
)
copy_parameters(trained_network, prediction_network)
return RepresentableBlockPredictor(
input_transform=transformation + prediction_splitter,
prediction_net=prediction_network,
batch_size=self.batch_size,
prediction_length=self.prediction_length,
ctx=self.trainer.ctx,
)
After defining the training and prediction network, as well as the estimator class, we can follow exactly the same steps as with the existing models, i.e., we can specify our estimator by passing all the required hyperparameters to the estimator class, train the estimator by invoking its train method to create a predictor, and finally use the make_evaluation_predictions function to generate our forecasts.
[64]:
estimator = MyEstimator(
prediction_length=custom_ds_metadata["prediction_length"],
context_length=2 * custom_ds_metadata["prediction_length"],
num_cells=40,
trainer=Trainer(
ctx="cpu",
epochs=5,
learning_rate=1e-3,
hybridize=False,
num_batches_per_epoch=100,
),
)
The estimator can be trained using our training dataset train_ds just by invoking its train method. The training returns a predictor that can be used to predict.
[65]:
predictor = estimator.train(train_ds)
100%|██████████| 100/100 [00:00<00:00, 257.30it/s, epoch=1/5, avg_epoch_loss=0.48]
100%|██████████| 100/100 [00:00<00:00, 268.75it/s, epoch=2/5, avg_epoch_loss=0.319]
100%|██████████| 100/100 [00:00<00:00, 288.90it/s, epoch=3/5, avg_epoch_loss=0.302]
100%|██████████| 100/100 [00:00<00:00, 296.54it/s, epoch=4/5, avg_epoch_loss=0.289]
100%|██████████| 100/100 [00:00<00:00, 284.35it/s, epoch=5/5, avg_epoch_loss=0.288]
[66]:
forecast_it, ts_it = make_evaluation_predictions(
dataset=test_ds, # test dataset
predictor=predictor, # predictor
num_samples=100, # number of sample paths we want for evaluation
)
[67]:
forecasts = list(forecast_it)
tss = list(ts_it)
[68]:
plt.plot(tss[0][-150:].to_timestamp())
forecasts[0].plot(show_label=True)
plt.legend()
[68]:
<matplotlib.legend.Legend at 0x7f2498018880>
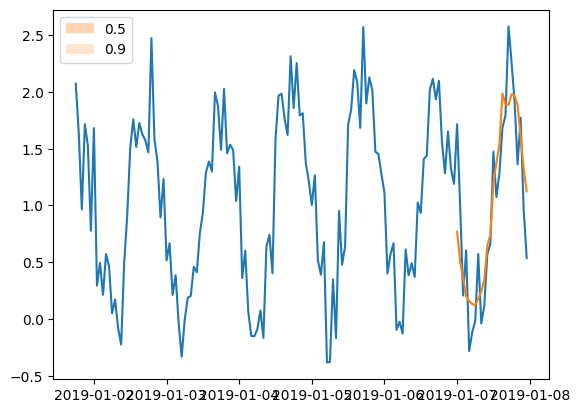
Observe that we cannot actually see any prediction intervals in the predictions. This is expected since the model that we defined does not do probabilistic forecasting but it just gives point estimates. By requiring 100 sample paths (defined in make_evaluation_predictions) in such a network, we get 100 times the same output.
Probabilistic forecasting#
How does a model learn a distribution?#
Probabilistic forecasting requires that we learn the distribution of the future values of the time series and not the values themselves as in point forecasting. To achieve this, we need to specify the type of distribution that the future values follow. GluonTS comes with a number of different distributions that cover many use cases, such as Gaussian, Student-t and Uniform just to name a few.
In order to learn a distribution we need to learn its parameters. For example, in the simple case where we assume a Gaussian distribution, we need to learn the mean and the variance that fully specify the distribution.
Each distribution that is available in GluonTS is defined by the corresponding Distribution class (e.g., Gaussian). This class defines -among others- the parameters of the distribution, its (log-)likelihood and a sampling method (given the parameters).
However, it is not straightforward how to connect a model with such a distribution and learn its parameters. For this, each distribution comes with a DistributionOutput class (e.g., GaussianOutput). The role of this class is to connect a model with a distribution. Its main usage is to take the output of the model and map it to the parameters of the distribution. You can think of it as an additional projection layer on top of the model. The parameters of this layer are optimized along
with the rest of the network.
By including this projection layer, our model effectively learns the parameters of the (chosen) distribution of each time step. Such a model is usually optimized by choosing as a loss function the negative log-likelihood of the chosen distribution. After we optimize our model and learn the parameters we can sample or derive any other useful statistics from the learned distributions.
Feedforward network for probabilistic forecasting#
Let’s see what changes we need to make to the previous model to make it probabilistic:
First, we need to change the output of the network. In the point forecast network the output was a vector of length
prediction_lengththat gave directly the point estimates. Now, we need to output a set of features that theDistributionOutputwill use to project to the distribution parameters. These features should be different for each time step at the prediction horizon. Therefore we need an overall output ofprediction_length * num_featuresvalues.The
DistributionOutputtakes as input a tensor and uses the last dimension as features to be projected to the distribution parameters. Here, we need a distribution object for each time step, i.e.,prediction_lengthdistribution objects. Given that the output of the network hasprediction_length * num_featuresvalues, we can reshape it to(prediction_length, num_features)and get the required distributions, while the last axis of lengthnum_featureswill be projected to the distribution parameters.We want the prediction network to output many sample paths for each time series. To achieve this we can repeat each time series as many times as the number of sample paths and do a standard forecast for each of them.
Note that in all the tensors that we handle there is an initial dimension that refers to the batch, e.g., the output of the network has dimension (batch_size, prediction_length * num_features).
[69]:
from gluonts.mx import DistributionOutput, GaussianOutput
[70]:
class MyProbNetwork(gluon.HybridBlock):
def __init__(
self, prediction_length, distr_output, num_cells, num_sample_paths=100, **kwargs
) -> None:
super().__init__(**kwargs)
self.prediction_length = prediction_length
self.distr_output = distr_output
self.num_cells = num_cells
self.num_sample_paths = num_sample_paths
self.proj_distr_args = distr_output.get_args_proj()
with self.name_scope():
# Set up a 2 layer neural network that its ouput will be projected to the distribution parameters
self.nn = mx.gluon.nn.HybridSequential()
self.nn.add(mx.gluon.nn.Dense(units=self.num_cells, activation="relu"))
self.nn.add(
mx.gluon.nn.Dense(
units=self.prediction_length * self.num_cells, activation="relu"
)
)
class MyProbTrainNetwork(MyProbNetwork):
def hybrid_forward(self, F, past_target, future_target):
# compute network output
net_output = self.nn(past_target)
# (batch, prediction_length * nn_features) -> (batch, prediction_length, nn_features)
net_output = net_output.reshape(0, self.prediction_length, -1)
# project network output to distribution parameters domain
distr_args = self.proj_distr_args(net_output)
# compute distribution
distr = self.distr_output.distribution(distr_args)
# negative log-likelihood
loss = distr.loss(future_target)
return loss
class MyProbPredNetwork(MyProbTrainNetwork):
# The prediction network only receives past_target and returns predictions
def hybrid_forward(self, F, past_target):
# repeat past target: from (batch_size, past_target_length) to
# (batch_size * num_sample_paths, past_target_length)
repeated_past_target = past_target.repeat(repeats=self.num_sample_paths, axis=0)
# compute network output
net_output = self.nn(repeated_past_target)
# (batch * num_sample_paths, prediction_length * nn_features) -> (batch * num_sample_paths, prediction_length, nn_features)
net_output = net_output.reshape(0, self.prediction_length, -1)
# project network output to distribution parameters domain
distr_args = self.proj_distr_args(net_output)
# compute distribution
distr = self.distr_output.distribution(distr_args)
# get (batch_size * num_sample_paths, prediction_length) samples
samples = distr.sample()
# reshape from (batch_size * num_sample_paths, prediction_length) to
# (batch_size, num_sample_paths, prediction_length)
return samples.reshape(
shape=(-1, self.num_sample_paths, self.prediction_length)
)
The changes we need to do at the estimator are minor and they mainly reflect the additional distr_output parameter that our networks use.
[71]:
class MyProbEstimator(GluonEstimator):
@validated()
def __init__(
self,
prediction_length: int,
context_length: int,
distr_output: DistributionOutput,
num_cells: int,
num_sample_paths: int = 100,
batch_size: int = 32,
trainer: Trainer = Trainer(),
) -> None:
super().__init__(trainer=trainer, batch_size=batch_size)
self.prediction_length = prediction_length
self.context_length = context_length
self.distr_output = distr_output
self.num_cells = num_cells
self.num_sample_paths = num_sample_paths
def create_transformation(self):
return Chain([])
def create_training_data_loader(self, dataset, **kwargs):
instance_splitter = InstanceSplitter(
target_field=FieldName.TARGET,
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=ExpectedNumInstanceSampler(
num_instances=1, min_future=self.prediction_length
),
past_length=self.context_length,
future_length=self.prediction_length,
)
input_names = get_hybrid_forward_input_names(MyProbTrainNetwork)
return TrainDataLoader(
dataset=dataset,
transform=instance_splitter + SelectFields(input_names),
batch_size=self.batch_size,
stack_fn=partial(batchify, ctx=self.trainer.ctx, dtype=self.dtype),
**kwargs,
)
def create_training_network(self) -> MyProbTrainNetwork:
return MyProbTrainNetwork(
prediction_length=self.prediction_length,
distr_output=self.distr_output,
num_cells=self.num_cells,
num_sample_paths=self.num_sample_paths,
)
def create_predictor(
self, transformation: Transformation, trained_network: HybridBlock
) -> Predictor:
prediction_splitter = InstanceSplitter(
target_field=FieldName.TARGET,
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=TestSplitSampler(),
past_length=self.context_length,
future_length=self.prediction_length,
)
prediction_network = MyProbPredNetwork(
prediction_length=self.prediction_length,
distr_output=self.distr_output,
num_cells=self.num_cells,
num_sample_paths=self.num_sample_paths,
)
copy_parameters(trained_network, prediction_network)
return RepresentableBlockPredictor(
input_transform=transformation + prediction_splitter,
prediction_net=prediction_network,
batch_size=self.batch_size,
prediction_length=self.prediction_length,
ctx=self.trainer.ctx,
)
[72]:
estimator = MyProbEstimator(
prediction_length=custom_ds_metadata["prediction_length"],
context_length=2 * custom_ds_metadata["prediction_length"],
distr_output=GaussianOutput(),
num_cells=40,
trainer=Trainer(
ctx="cpu",
epochs=5,
learning_rate=1e-3,
hybridize=False,
num_batches_per_epoch=100,
),
)
[73]:
predictor = estimator.train(train_ds)
100%|██████████| 100/100 [00:00<00:00, 218.24it/s, epoch=1/5, avg_epoch_loss=0.793]
100%|██████████| 100/100 [00:00<00:00, 218.60it/s, epoch=2/5, avg_epoch_loss=0.399]
100%|██████████| 100/100 [00:00<00:00, 192.27it/s, epoch=3/5, avg_epoch_loss=0.371]
100%|██████████| 100/100 [00:00<00:00, 223.83it/s, epoch=4/5, avg_epoch_loss=0.351]
100%|██████████| 100/100 [00:00<00:00, 222.29it/s, epoch=5/5, avg_epoch_loss=0.343]
[74]:
forecast_it, ts_it = make_evaluation_predictions(
dataset=test_ds, # test dataset
predictor=predictor, # predictor
num_samples=100, # number of sample paths we want for evaluation
)
[75]:
forecasts = list(forecast_it)
tss = list(ts_it)
[76]:
plt.plot(tss[0][-150:].to_timestamp())
forecasts[0].plot(show_label=True)
plt.legend()
[76]:
<matplotlib.legend.Legend at 0x7f249808ac40>
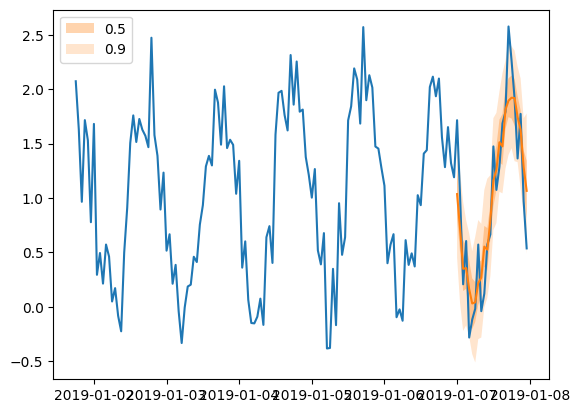
Add features and scaling#
In the previous networks we used only the target and did not leverage any of the features of the dataset. Here we expand the probabilistic network by including the feat_dynamic_real field of the dataset that could enhance the forecasting power of our model. We achieve this by concatenating the target and the features to an enhanced vector that forms the new network input.
All the features that are available in a dataset can be potentially used as inputs to our model. However, for the purposes of this example we will restrict ourselves to using only one feature.
An important issue that a practitioner needs to deal with often is the different orders of magnitude in the values of the time series in a dataset. It is extremely helpful for a model to be trained and forecast values that lie roughly in the same value range. To address this issue, we add a Scaler to out model, that computes the scale of each time series. Then we can scale accordingly the values of the time series or any related features and use these as inputs to the network.
[77]:
from gluonts.mx import MeanScaler, NOPScaler
[78]:
class MyProbNetwork(gluon.HybridBlock):
def __init__(
self,
prediction_length,
context_length,
distr_output,
num_cells,
num_sample_paths=100,
scaling=True,
**kwargs
) -> None:
super().__init__(**kwargs)
self.prediction_length = prediction_length
self.context_length = context_length
self.distr_output = distr_output
self.num_cells = num_cells
self.num_sample_paths = num_sample_paths
self.proj_distr_args = distr_output.get_args_proj()
self.scaling = scaling
with self.name_scope():
# Set up a 2 layer neural network that its ouput will be projected to the distribution parameters
self.nn = mx.gluon.nn.HybridSequential()
self.nn.add(mx.gluon.nn.Dense(units=self.num_cells, activation="relu"))
self.nn.add(
mx.gluon.nn.Dense(
units=self.prediction_length * self.num_cells, activation="relu"
)
)
if scaling:
self.scaler = MeanScaler(keepdims=True)
else:
self.scaler = NOPScaler(keepdims=True)
def compute_scale(self, past_target, past_observed_values):
# scale shape is (batch_size, 1)
_, scale = self.scaler(
past_target.slice_axis(axis=1, begin=-self.context_length, end=None),
past_observed_values.slice_axis(
axis=1, begin=-self.context_length, end=None
),
)
return scale
class MyProbTrainNetwork(MyProbNetwork):
def hybrid_forward(
self,
F,
past_target,
future_target,
past_observed_values,
past_feat_dynamic_real,
):
# compute scale
scale = self.compute_scale(past_target, past_observed_values)
# scale target and time features
past_target_scale = F.broadcast_div(past_target, scale)
past_feat_dynamic_real_scale = F.broadcast_div(
past_feat_dynamic_real.squeeze(axis=-1), scale
)
# concatenate target and time features to use them as input to the network
net_input = F.concat(past_target_scale, past_feat_dynamic_real_scale, dim=-1)
# compute network output
net_output = self.nn(net_input)
# (batch, prediction_length * nn_features) -> (batch, prediction_length, nn_features)
net_output = net_output.reshape(0, self.prediction_length, -1)
# project network output to distribution parameters domain
distr_args = self.proj_distr_args(net_output)
# compute distribution
distr = self.distr_output.distribution(distr_args, scale=scale)
# negative log-likelihood
loss = distr.loss(future_target)
return loss
class MyProbPredNetwork(MyProbTrainNetwork):
# The prediction network only receives past_target and returns predictions
def hybrid_forward(
self, F, past_target, past_observed_values, past_feat_dynamic_real
):
# repeat fields: from (batch_size, past_target_length) to
# (batch_size * num_sample_paths, past_target_length)
repeated_past_target = past_target.repeat(repeats=self.num_sample_paths, axis=0)
repeated_past_observed_values = past_observed_values.repeat(
repeats=self.num_sample_paths, axis=0
)
repeated_past_feat_dynamic_real = past_feat_dynamic_real.repeat(
repeats=self.num_sample_paths, axis=0
)
# compute scale
scale = self.compute_scale(repeated_past_target, repeated_past_observed_values)
# scale repeated target and time features
repeated_past_target_scale = F.broadcast_div(repeated_past_target, scale)
repeated_past_feat_dynamic_real_scale = F.broadcast_div(
repeated_past_feat_dynamic_real.squeeze(axis=-1), scale
)
# concatenate target and time features to use them as input to the network
net_input = F.concat(
repeated_past_target_scale, repeated_past_feat_dynamic_real_scale, dim=-1
)
# compute network oputput
net_output = self.nn(net_input)
# (batch * num_sample_paths, prediction_length * nn_features) -> (batch * num_sample_paths, prediction_length, nn_features)
net_output = net_output.reshape(0, self.prediction_length, -1)
# project network output to distribution parameters domain
distr_args = self.proj_distr_args(net_output)
# compute distribution
distr = self.distr_output.distribution(distr_args, scale=scale)
# get (batch_size * num_sample_paths, prediction_length) samples
samples = distr.sample()
# reshape from (batch_size * num_sample_paths, prediction_length) to
# (batch_size, num_sample_paths, prediction_length)
return samples.reshape(
shape=(-1, self.num_sample_paths, self.prediction_length)
)
[79]:
class MyProbEstimator(GluonEstimator):
@validated()
def __init__(
self,
prediction_length: int,
context_length: int,
distr_output: DistributionOutput,
num_cells: int,
num_sample_paths: int = 100,
scaling: bool = True,
batch_size: int = 32,
trainer: Trainer = Trainer(),
) -> None:
super().__init__(trainer=trainer, batch_size=batch_size)
self.prediction_length = prediction_length
self.context_length = context_length
self.distr_output = distr_output
self.num_cells = num_cells
self.num_sample_paths = num_sample_paths
self.scaling = scaling
def create_transformation(self):
# Feature transformation that the model uses for input.
return AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
)
def create_training_data_loader(self, dataset, **kwargs):
instance_splitter = InstanceSplitter(
target_field=FieldName.TARGET,
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=ExpectedNumInstanceSampler(
num_instances=1, min_future=self.prediction_length
),
past_length=self.context_length,
future_length=self.prediction_length,
time_series_fields=[
FieldName.FEAT_DYNAMIC_REAL,
FieldName.OBSERVED_VALUES,
],
)
input_names = get_hybrid_forward_input_names(MyProbTrainNetwork)
return TrainDataLoader(
dataset=dataset,
transform=instance_splitter + SelectFields(input_names),
batch_size=self.batch_size,
stack_fn=partial(batchify, ctx=self.trainer.ctx, dtype=self.dtype),
**kwargs,
)
def create_training_network(self) -> MyProbTrainNetwork:
return MyProbTrainNetwork(
prediction_length=self.prediction_length,
context_length=self.context_length,
distr_output=self.distr_output,
num_cells=self.num_cells,
num_sample_paths=self.num_sample_paths,
scaling=self.scaling,
)
def create_predictor(
self, transformation: Transformation, trained_network: HybridBlock
) -> Predictor:
prediction_splitter = InstanceSplitter(
target_field=FieldName.TARGET,
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=TestSplitSampler(),
past_length=self.context_length,
future_length=self.prediction_length,
time_series_fields=[
FieldName.FEAT_DYNAMIC_REAL,
FieldName.OBSERVED_VALUES,
],
)
prediction_network = MyProbPredNetwork(
prediction_length=self.prediction_length,
context_length=self.context_length,
distr_output=self.distr_output,
num_cells=self.num_cells,
num_sample_paths=self.num_sample_paths,
scaling=self.scaling,
)
copy_parameters(trained_network, prediction_network)
return RepresentableBlockPredictor(
input_transform=transformation + prediction_splitter,
prediction_net=prediction_network,
batch_size=self.batch_size,
prediction_length=self.prediction_length,
ctx=self.trainer.ctx,
)
[80]:
estimator = MyProbEstimator(
prediction_length=custom_ds_metadata["prediction_length"],
context_length=2 * custom_ds_metadata["prediction_length"],
distr_output=GaussianOutput(),
num_cells=40,
trainer=Trainer(
ctx="cpu",
epochs=5,
learning_rate=1e-3,
hybridize=False,
num_batches_per_epoch=100,
),
)
[81]:
predictor = estimator.train(train_ds)
100%|██████████| 100/100 [00:00<00:00, 119.95it/s, epoch=1/5, avg_epoch_loss=0.967]
100%|██████████| 100/100 [00:00<00:00, 123.75it/s, epoch=2/5, avg_epoch_loss=0.536]
100%|██████████| 100/100 [00:00<00:00, 135.19it/s, epoch=3/5, avg_epoch_loss=0.483]
100%|██████████| 100/100 [00:00<00:00, 126.54it/s, epoch=4/5, avg_epoch_loss=0.455]
100%|██████████| 100/100 [00:00<00:00, 122.88it/s, epoch=5/5, avg_epoch_loss=0.431]
[82]:
forecast_it, ts_it = make_evaluation_predictions(
dataset=test_ds, # test dataset
predictor=predictor, # predictor
num_samples=100, # number of sample paths we want for evaluation
)
[83]:
forecasts = list(forecast_it)
tss = list(ts_it)
[84]:
plt.plot(tss[0][-150:].to_timestamp())
forecasts[0].plot(show_label=True)
plt.legend()
[84]:
<matplotlib.legend.Legend at 0x7f24cf974ac0>
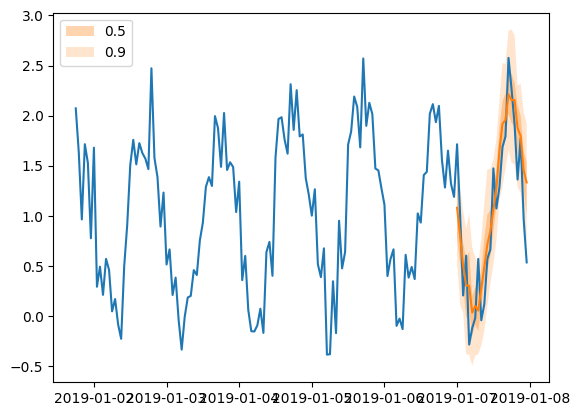
From feedforward to RNN#
In all the previous examples we have used a feedforward neural network as the base for our forecasting model. The main idea behind it was to use as an input to the network a window of the time series (of length context_length) and train the network to forecast the following window (of length prediction_length).
In this section we will replace the feedforward network with a recurrent neural network (RNN). Due to the different nature of RNNs the structure of the networks will be a bit different. Let’s see what are the major changes.
Training#
The main idea behind RNN is the same as in the feedforward networks we already constructed: as we unroll the RNN at each time step we use as an input past values of the time series and forecast the next value. We can enhance the input by using multiple past values (for example specific lags based on seasonality patterns) or available features. However, in this example we will keep things simple and just use the last value of the time series. The output of the network at each time step is the distribution of the value of the next time step, where the state of the RNN is used as the feature vector for the parameter projection of the distribution.
Due to the sequential nature of the RNN, the distinction between past_ and future_ in the cut window of the time series is not really necessary. Therefore, we can concatenate past_target and future_target and treat it as a concrete target window that we wish to forecast. This means that the input to the RNN would be (sequentially) the window target[-(context_length + prediction_length + 1):-1] (one time step before the window we want to predict). As a consequence, we need
to have context_length + prediction_length + 1 available values at each window that we cut. We can define this in the InstanceSplitter.
Overall, during training the steps are the following:
We pass sequentially through the RNN the target values
target[-(context_length + prediction_length + 1):-1]We use the state of the RNN at each time step as a feature vector and project it to the distribution parameter domain
The output at each time step is the distribution of the values of the next time step, which overall is the forecasted distribution for the window
target[-(context_length + prediction_length):]
The above steps are implemented in the unroll_encoder method.
Inference#
During inference we know the values only of past_target therefore we cannot follow exactly the same steps as in training. However the main idea is very similar:
We pass sequentially through the RNN the past target values
past_target[-(context_length + 1):]that effectively updates the state of the RNNIn the last time step the output of the RNN is effectively the distribution of the next value of the time series (which we do not know). Therefore we sample (
num_sample_pathstimes) from this distribution and use the samples as inputs to the RNN for the next time stepWe repeat the previous step
prediction_lengthtimes
The first step is implemented in unroll_encoder and the last steps in the sample_decoder method.
[85]:
class MyProbRNN(gluon.HybridBlock):
def __init__(
self,
prediction_length,
context_length,
distr_output,
num_cells,
num_layers,
num_sample_paths=100,
scaling=True,
**kwargs
) -> None:
super().__init__(**kwargs)
self.prediction_length = prediction_length
self.context_length = context_length
self.distr_output = distr_output
self.num_cells = num_cells
self.num_layers = num_layers
self.num_sample_paths = num_sample_paths
self.proj_distr_args = distr_output.get_args_proj()
self.scaling = scaling
with self.name_scope():
self.rnn = mx.gluon.rnn.HybridSequentialRNNCell()
for k in range(self.num_layers):
cell = mx.gluon.rnn.LSTMCell(hidden_size=self.num_cells)
cell = mx.gluon.rnn.ResidualCell(cell) if k > 0 else cell
self.rnn.add(cell)
if scaling:
self.scaler = MeanScaler(keepdims=True)
else:
self.scaler = NOPScaler(keepdims=True)
def compute_scale(self, past_target, past_observed_values):
# scale is computed on the context length last units of the past target
# scale shape is (batch_size, 1, *target_shape)
_, scale = self.scaler(
past_target.slice_axis(axis=1, begin=-self.context_length, end=None),
past_observed_values.slice_axis(
axis=1, begin=-self.context_length, end=None
),
)
return scale
def unroll_encoder(
self,
F,
past_target,
past_observed_values,
future_target=None,
future_observed_values=None,
):
# overall target field
# input target from -(context_length + prediction_length + 1) to -1
if future_target is not None: # during training
target_in = F.concat(past_target, future_target, dim=-1).slice_axis(
axis=1,
begin=-(self.context_length + self.prediction_length + 1),
end=-1,
)
# overall observed_values field
# input observed_values corresponding to target_in
observed_values_in = F.concat(
past_observed_values, future_observed_values, dim=-1
).slice_axis(
axis=1,
begin=-(self.context_length + self.prediction_length + 1),
end=-1,
)
rnn_length = self.context_length + self.prediction_length
else: # during inference
target_in = past_target.slice_axis(
axis=1, begin=-(self.context_length + 1), end=-1
)
# overall observed_values field
# input observed_values corresponding to target_in
observed_values_in = past_observed_values.slice_axis(
axis=1, begin=-(self.context_length + 1), end=-1
)
rnn_length = self.context_length
# compute scale
scale = self.compute_scale(target_in, observed_values_in)
# scale target_in
target_in_scale = F.broadcast_div(target_in, scale)
# compute network output
net_output, states = self.rnn.unroll(
inputs=target_in_scale,
length=rnn_length,
layout="NTC",
merge_outputs=True,
)
return net_output, states, scale
class MyProbTrainRNN(MyProbRNN):
def hybrid_forward(
self,
F,
past_target,
future_target,
past_observed_values,
future_observed_values,
):
net_output, _, scale = self.unroll_encoder(
F, past_target, past_observed_values, future_target, future_observed_values
)
# output target from -(context_length + prediction_length) to end
target_out = F.concat(past_target, future_target, dim=-1).slice_axis(
axis=1, begin=-(self.context_length + self.prediction_length), end=None
)
# project network output to distribution parameters domain
distr_args = self.proj_distr_args(net_output)
# compute distribution
distr = self.distr_output.distribution(distr_args, scale=scale)
# negative log-likelihood
loss = distr.loss(target_out)
return loss
class MyProbPredRNN(MyProbTrainRNN):
def sample_decoder(self, F, past_target, states, scale):
# repeat fields: from (batch_size, past_target_length) to
# (batch_size * num_sample_paths, past_target_length)
repeated_states = [
s.repeat(repeats=self.num_sample_paths, axis=0) for s in states
]
repeated_scale = scale.repeat(repeats=self.num_sample_paths, axis=0)
# first decoder input is the last value of the past_target, i.e.,
# the previous value of the first time step we want to forecast
decoder_input = past_target.slice_axis(axis=1, begin=-1, end=None).repeat(
repeats=self.num_sample_paths, axis=0
)
# list with samples at each time step
future_samples = []
# for each future time step we draw new samples for this time step and update the state
# the drawn samples are the inputs to the rnn at the next time step
for k in range(self.prediction_length):
rnn_outputs, repeated_states = self.rnn.unroll(
inputs=decoder_input,
length=1,
begin_state=repeated_states,
layout="NTC",
merge_outputs=True,
)
# project network output to distribution parameters domain
distr_args = self.proj_distr_args(rnn_outputs)
# compute distribution
distr = self.distr_output.distribution(distr_args, scale=repeated_scale)
# draw samples (batch_size * num_samples, 1)
new_samples = distr.sample()
# append the samples of the current time step
future_samples.append(new_samples)
# update decoder input for the next time step
decoder_input = new_samples
samples = F.concat(*future_samples, dim=1)
# (batch_size, num_samples, prediction_length)
return samples.reshape(
shape=(-1, self.num_sample_paths, self.prediction_length)
)
def hybrid_forward(self, F, past_target, past_observed_values):
# unroll encoder over context_length
net_output, states, scale = self.unroll_encoder(
F, past_target, past_observed_values
)
samples = self.sample_decoder(F, past_target, states, scale)
return samples
[86]:
class MyProbRNNEstimator(GluonEstimator):
@validated()
def __init__(
self,
prediction_length: int,
context_length: int,
distr_output: DistributionOutput,
num_cells: int,
num_layers: int,
num_sample_paths: int = 100,
scaling: bool = True,
batch_size: int = 32,
trainer: Trainer = Trainer(),
) -> None:
super().__init__(trainer=trainer, batch_size=batch_size)
self.prediction_length = prediction_length
self.context_length = context_length
self.distr_output = distr_output
self.num_cells = num_cells
self.num_layers = num_layers
self.num_sample_paths = num_sample_paths
self.scaling = scaling
def create_transformation(self):
# Feature transformation that the model uses for input.
return AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
)
def create_training_data_loader(self, dataset, **kwargs):
instance_splitter = InstanceSplitter(
target_field=FieldName.TARGET,
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=ExpectedNumInstanceSampler(
num_instances=1,
min_future=self.prediction_length,
),
past_length=self.context_length + 1,
future_length=self.prediction_length,
time_series_fields=[
FieldName.FEAT_DYNAMIC_REAL,
FieldName.OBSERVED_VALUES,
],
)
input_names = get_hybrid_forward_input_names(MyProbTrainRNN)
return TrainDataLoader(
dataset=dataset,
transform=instance_splitter + SelectFields(input_names),
batch_size=self.batch_size,
stack_fn=partial(batchify, ctx=self.trainer.ctx, dtype=self.dtype),
**kwargs,
)
def create_training_network(self) -> MyProbTrainRNN:
return MyProbTrainRNN(
prediction_length=self.prediction_length,
context_length=self.context_length,
distr_output=self.distr_output,
num_cells=self.num_cells,
num_layers=self.num_layers,
num_sample_paths=self.num_sample_paths,
scaling=self.scaling,
)
def create_predictor(
self, transformation: Transformation, trained_network: HybridBlock
) -> Predictor:
prediction_splitter = InstanceSplitter(
target_field=FieldName.TARGET,
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=TestSplitSampler(),
past_length=self.context_length + 1,
future_length=self.prediction_length,
time_series_fields=[
FieldName.FEAT_DYNAMIC_REAL,
FieldName.OBSERVED_VALUES,
],
)
prediction_network = MyProbPredRNN(
prediction_length=self.prediction_length,
context_length=self.context_length,
distr_output=self.distr_output,
num_cells=self.num_cells,
num_layers=self.num_layers,
num_sample_paths=self.num_sample_paths,
scaling=self.scaling,
)
copy_parameters(trained_network, prediction_network)
return RepresentableBlockPredictor(
input_transform=transformation + prediction_splitter,
prediction_net=prediction_network,
batch_size=self.batch_size,
prediction_length=self.prediction_length,
ctx=self.trainer.ctx,
)
[87]:
estimator = MyProbRNNEstimator(
prediction_length=24,
context_length=48,
num_cells=40,
num_layers=2,
distr_output=GaussianOutput(),
trainer=Trainer(
ctx="cpu",
epochs=5,
learning_rate=1e-3,
hybridize=False,
num_batches_per_epoch=100,
),
)
[88]:
predictor = estimator.train(train_ds)
100%|██████████| 100/100 [00:16<00:00, 6.03it/s, epoch=1/5, avg_epoch_loss=0.752]
100%|██████████| 100/100 [00:16<00:00, 6.03it/s, epoch=2/5, avg_epoch_loss=0.394]
100%|██████████| 100/100 [00:16<00:00, 5.88it/s, epoch=3/5, avg_epoch_loss=0.342]
100%|██████████| 100/100 [00:16<00:00, 6.06it/s, epoch=4/5, avg_epoch_loss=0.294]
100%|██████████| 100/100 [00:16<00:00, 5.96it/s, epoch=5/5, avg_epoch_loss=0.268]
[89]:
forecast_it, ts_it = make_evaluation_predictions(
dataset=test_ds, # test dataset
predictor=predictor, # predictor
num_samples=100, # number of sample paths we want for evaluation
)
[90]:
forecasts = list(forecast_it)
tss = list(ts_it)
[91]:
plt.plot(tss[0][-150:].to_timestamp())
forecasts[0].plot(show_label=True)
plt.legend()
[91]:
<matplotlib.legend.Legend at 0x7f2498159640>